3. 表・セルのマッピング方法
表やセルをマッピングするためには様々なアノテーションが用意されています。
様々な表に対応するため、マッピング方法を指定するためのアノテーションと補助的に詳細なオプションを指定するためのアノテーションがあります。
もし、独自の構造の表をマッピングするならば、「独自の表・セルのマッピング方法」を参照してください。
アノテーション |
概要 |
|---|---|
シートをマッピングするためにクラスに付与し使用します。 |
|
シート名をマッピングします。 |
|
セルの座標を直接指定してマッピングします。 |
|
見出し付きのセルをマッピングします。 |
|
連続し隣接するセルを配列またはリストにマッピングします。 |
|
見出し付きの連続し隣接するセルを配列またはリストにマッピングします。 |
|
水平方向に連続する行のレコードを持つ表をマッピングします。 |
|
垂直方向に連続する列のレコードを持つ表をマッピングします。 |
|
レコードのカラムをマッピングします。 |
|
レコードの可変長のカラムをマッピングします。 |
|
レコードの隣接するカラムをマッピングします。 |
|
入れ子構造のレコードをマッピングします。 |
|
シート内で繰り返される同一構造の表をマッピングします。 |
|
セルの座標を直接指定して、セルのコメントをマッピングします。 |
|
指定したラベルセルのコメント情報をマッピングします。 |
アノテーション |
概要 |
|---|---|
フィールドの処理順序を指定するために使用します。 |
|
レコードを読み飛ばすことが可能か判定するためのメソッドに使用します。 |
|
連続し隣接するセルを配列またはリストを書き込む際の制御を行います。 |
|
レコードを書き込む際の制御を行います。 |
|
レコードの開始位置をプログラマティックに指定します。 |
|
書き込み時のセルのコメントのサイズなどの制御を指定します。 |
3.1. @XlsSheet
マッピング対象のシートを「シート番号」「シート名」「シート名に対する正規表現」のいずれかで指定します。
クラスに付与します。
1@XlsSheet(number=0)
2public class SampleSheet {
3 ...
4}
1@XlsSheet(name="Users")
2public class SampleSheet {
3 ...
4}
1@XlsSheet(regex="Users.+")
2public class SampleSheet {
3 ...
4}
3.1.1. シート名を正規表現で指定する場合
正規表現で指定する場合は、 XlsMapper#loadMultiple(...) メソッドを用いることで、同じ形式の一致した複数シートの情報を一度に取得できます。
書き込み時は、複数のシートが一致する可能性があり、1つに特定できない場合があるため注意が必要です。
正規表現に一致するシートが1つしかない場合は、そのまま書き込みます。[ver0.5+]
正規表現に一致するシートが複数ある場合、アノテーション @XlsSheetName を付与したフィールドの値を元に決定します。 そのため、予めフィールドに設定しておく必要があります。
アノテーション @XlsSheetName を付与しているフィールドを指定し、その値に一致しなくても、正規表現に一致するシートが1つ一致すれば、そのシートに書き込まれます。[ver0.5+]
1@XlsSheet(regex="Sheet_[0-9]+")
2public class SampleSheet {
3
4 // シート名をマッピングするフィールド
5 @XlsSheetName
6 private String sheetName;
7 ...
8}
9
10
11// 正規表現による複数のシートを出力する場合。
12// 書き込み時に、シート名を設定して、一意に関連づけます。
13SampleSheet sheet1 = new SampleSheet();
14sheet1.sheetName = "Sheet_1"; // シート名の設定
15
16SampleSheet sheet2 = new SampleSheet();
17sheet2.sheetName = "Sheet_2"; // シート名の設定
18
19SampleSheet sheet3 = new SampleSheet();
20sheet3.sheetName = "Sheet_3"; // シート名の設定
21
22// 複数のシートの書き込み
23XlsMapper xlsMapper = new XlsMapper();
24xlsMapper.saveMultiple(new FileInputStream("template.xls"),
25 new FileOutputStream("out.xls"),
26 new Object[]{sheet1, sheet2, sheet3}
27);
動的に書き込むシート数が変わるような場合は、下記のように、テンプレート用のシートをコピーしてから処理を行います。
1// 正規表現による複数のシートを出力する場合。
2// 書き込み時に、シート名を設定して、一意に関連づけます。
3SampleSheet sheet1 = new SampleSheet();
4sheet1.sheetName = "Sheet_1"; // シート名の設定
5
6SampleSheet sheet2 = new SampleSheet();
7sheet2.sheetName = "Sheet_2"; // シート名の設定
8
9SampleSheet sheet3 = new SampleSheet();
10sheet3.sheetName = "Sheet_3"; // シート名の設定
11
12SampleSheet[] sheets = new SampleSheet[]{sheet1, sheet2, sheet3};
13
14// シートのクローン
15Workbook workbook = WorkbookFactory.create(new FileInputStream("template.xlsx"));
16Sheet templateSheet = workbook.getSheet("XlsSheet(regexp)");
17for(SampleSheet sheetObj : sheets) {
18 int sheetIndex = workbook.getSheetIndex(templateSheet);
19 Sheet cloneSheet = workbook.cloneSheet(sheetIndex);
20 workbook.setSheetName(workbook.getSheetIndex(cloneSheet), sheetObj.sheetName);
21}
22
23// コピー元のシートを削除する
24workbook.removeSheetAt(workbook.getSheetIndex(templateSheet));
25
26// クローンしたシートファイルを、一時ファイルに一旦出力する。
27File cloneTemplateFile = File.createTempFile("template", ".xlsx");
28workbook.write(new FileOutputStream(cloneTemplateFile));
29
30// 複数のシートの書き込み
31XlsMapper xlsMapper = new XlsMapper();
32xlsMapper.saveMultiple(
33 new FileInputStream(cloneTemplateFile), // クローンしたシートを持つファイルを指定する
34 new FileOutputStream("out.xlsx"),
35 sheets);
3.2. @XlsSheetName
シート名をString型のプロパティにマッピングします。
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsSheetName
5 private String sheetName;
6}
注釈
書き込み時に、アノテーション @XlsSheet(regex="<シート名>") にて、
シート名を正規表現で指定している場合は、 @XlsSheetName を付与しているフィールドで書き込むシートを決定します。
そのため書き込む前に、シート名を指定する必要があります。
3.2.1. メソッドにアノテーションを付与する場合
アノテーションをメソッドに付与する場合、書き込み時はgetterメソッドメソッドの付与が必要になります。
さらに、アノテーションは付与しなくてもよいですが、setterメソッドの定義が必要になります。
そのため、 @XlsSheetName を指定する際にはフィールドに付与することをお薦めします。
1// 読み込み時は、setterメソッドに付与する。
2@XlsSheet(name="Users")
3public class SheetObject {
4
5 private String sheetName;
6
7 // 読み込み時は、setterメソッドにアノテーションの付与が必要。
8 @XlsSheetName
9 public void setSheetName(String sheetName) {
10 return sheetName;
11 }
12
13}
1// 書き込み時は、getterメソッドに付与し、かつsetterメソッドの定義が必要。
2@XlsSheet(name="Users")
3public class SampleSheet {
4
5 private String sheetName;
6
7 // 書き込み時は、getterメソッドにアノテーションの付与が必要。
8 @XlsSheetName
9 public String getSheetName() {
10 return sheetName;
11 }
12
13 // アノテーションの付与は必要ないが、定義が必要。
14 public void setSheetName(String sheetName) {
15 return sheetName;
16 }
17
18}
3.3. @XlsCell
セルの列と行を指定してBeanのプロパティにマッピングします。
フィールドまたはメソッドに対して付与します。
属性
column、rowで、インデックスを指定します。columnは列番号で、0から始まります。
rowは行番号で、0から始まります。
属性
addressで、 'B3' のようにシートのアドレス形式で指定もできます。属性addressを指定する場合は、column, rowは指定しないでください。
属性addressの両方を指定した場合、addressの値が優先されます。
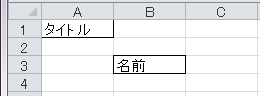
図 - 3.3.1 Cell
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // インデックス形式で指定する場合
5 @XlsCell(column=0, row=0)
6 private String title;
7
8 // アドレス形式で指定する場合
9 @XlsCell(address="B3")
10 private String name;
11
12}
3.4. @XlsLabelledCell
セルの見出し用のラベルセルを指定し、その左右もしくは下側のセルの値をマッピングします。
フィールドまたはメソッドに対して付与します。
属性
labelで、見出しとなるセルの値を指定します。属性
typeで、見出しセルから見て値が設定されている位置を指定します。列挙型
LabelledCellTypeで、左右もしくは下側のセルを指定できます。
属性
optionalで、見出しとなるセルが見つからない場合に無視するかどうかを指定しできます。
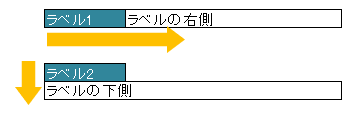
図 - 3.4.1 LabelledCell
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledCell(label="ラベル1", type=LabelledCellType.Right)
5 private String title;
6
7 // ラベルセルが見つからなくても処理を続行する
8 @XlsLabelledCell(label="ラベル2", type=LabelledCellType.Bottom, optional=true)
9 private String summary;
10}
3.4.1. ラベルセルから離れたセルを指定する方法(属性range)
属性 range を指定すると、属性typeの方向に向かって指定した セル数分を検索 し、最初に発見した空白以外のセルの値を取得します。
属性
rangeとskipを同時に指定した場合、まず、skip分セルを読み飛ばし、そこからrangeの範囲で空白以外のセルを検索します。属性
rangeは、 読み込み時のみ有効 です。書き込み時に指定しても無視されます。
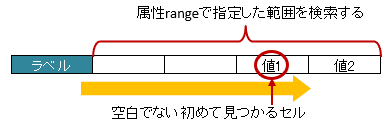
図 - 3.4.2 LabelledCell(range)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledCell(label="ラベル", type=LabelledCellType.Right, range=4)
5 private String title;
6
7}
3.4.2. ラベルセルから離れたセルを指定する方法(属性skip)
属性 skip を指定すると、属性typeの方向に向かって指定した セル数分離れた セルの値をマッピングできます。
属性
rangeとskipを同時に指定した場合、まず、skip分セルを読み飛ばし、そこからrangeの範囲で空白以外のセルを検索します。
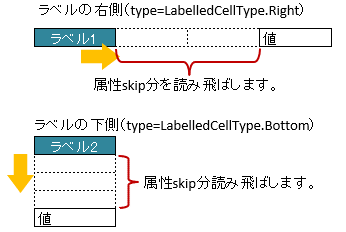
図 - 3.4.3 LabelledCell(skip)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledCell(label="ラベル1", type=LabelledCellType.Right, skip=2)
5 private String title1;
6
7 @XlsLabelledCell(label="ラベル2", type=LabelledCellType.Bottom, skip=3)
8 private String title2;
9
10}
3.4.3. ラベルセルが結合している場合(属性labelMerged)
属性
labelMergedで、見出しのラベルセルが結合を考慮するか指定します。 [ver.2.0+]trueのときは、結合されているセルを1つのラベルセルとしてマッピングします。
falseの場合は、結合されていても解除した状態と同じマッピング結果となります。
初期値はtrueであるため、特に意識はする必要はありません。
属性
labelMergedの値がfalseのとき、ラベルセルが結合されていると、値が設定されているデータセルまでの距離が変わるため、属性skipを併用します。
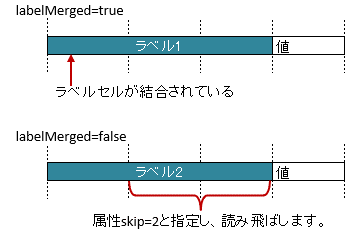
図 - 3.4.4 LabelledCell(labelMerged)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // labelMerged=trueは初期値なので、省略可
5 @XlsLabelledCell(label="ラベル1", type=LabelledCellType.Right)
6 private String title1;
7
8 // labelMerged=falseで、ラベルが結合しているときは、skip属性を併用します。
9 @XlsLabelledCell(label="ラベル2", type=LabelledCellType.Right, labelMerged=false, skip=2)
10 private String title2;
11
12}
3.4.4. ラベルセルが重複するセルを指定する方法
同じラベルのセルが複数ある場合は、区別するための見出しを属性 headerLabel で指定します。
属性headerLabelで指定したセルから、label属性で指定したセルを下方向に検索し、最初に見つかった一致するセルをラベルセルとして使用します。
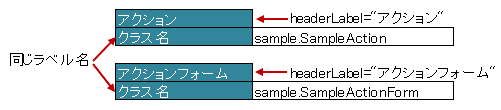
図 - 3.4.5 LabelledCell(headerLabel)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledCell(label="クラス名", type=LabelledCellType.Right,
5 headerLabel="アクション")
6 private String actionClassName;
7
8 @XlsLabelledCell(label="クラス名", type=LabelledCellType.Right,
9 headerLabel="アクションフォーム")
10 private String formClassName;
11
12}
3.4.5. ラベルセルを正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し、正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、label , headerLabel です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// シート用クラス
8@XlsSheet(name="Users")
9public class SampleSheet {
10
11 // 正規表現による指定
12 @XlsLabelledCell(label="/名前.+/", type=LabelledCellType.Right)
13 private String className;
14
15}
3.5. @XlsArrayCells
連続し隣接するセルをCollection(List, Set)または配列にマッピングします。 [ver.2.0+]
属性
column、rowで、セルの位置をインデックスで指定します。columnは列番号で、0から始まります。
rowは行番号で、0から始まります。
属性
addressで、 'B3' のようにシートのアドレス形式で指定もできます。属性addressを指定する場合は、column, rowは指定しないでください。
属性addressの両方を指定した場合、addressの値が優先されます。
属性
directionで、連続する隣接するセルの方向を指定します。列挙型
ArrayDirectionで、横方向(右方向)もしくは、直方向(下方向)を指定できます。初期値は、横方向(右方向)です。
属性
sizeで、連続するセルの個数を指定します。Collection(List, Set)型または配列のフィールドに付与します。
List型などの場合、Genericsのタイプとして、マッピング先のクラスを指定します。
指定しない場合は、アノテーションの属性
elementClassでクラス型を指定します。
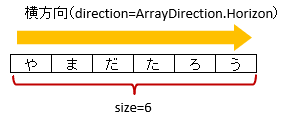
図 - 3.5.1 ArrayCells
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // インデックス形式、横方向で指定する場合
5 // 属性directionを省略した場合は、ArrayDirection.Horizonを指定したと同じ意味。
6 @XlsArrayCells(column=0, row=0, size=6)
7 private List<String> nameKanas1;
8
9 // アドレス形式、配列にマッピング
10 @XlsArrayCells(address="A1", size=6, direction=ArrayDirection.Horizon)
11 private String[] nameKanas2;
12
13}
3.5.1. 縦方向に隣接したセルをマッピングする場合
縦方向にマッピングするため、属性
directionを、ArrayDirection.Verticalに設定します。

図 - 3.5.2 ArrayCells(direction)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // 縦方向の隣接するセル
5 // 属性direction=ArrayDirection.Verticalを指定すると、縦方向にマッピングします。
6 @XlsLabelledArrayCells(address="B3", direction=ArrayDirection.Vertical, size=4)
7 private List<String> names;
8}
3.5.2. 結合したセルをマッピングする場合
属性
elementMergedで、セルの結合を考慮するか指定します。trueのときは、結合されているセルを1つのセルとしてマッピングします。
falseの場合は、結合されていても解除した状態と同じマッピング結果となります。
ただし、falseのときは、書き込む際には結合が解除されます。
初期値はtrueであるため、特に意識はする必要はありません。
セルが結合されている場合は、結合後の個数を指定します。
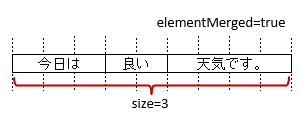
図 - 3.5.3 ArrayCells(elementMerged)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // elementMerged=trueは初期値なので、省略可
5 @XlsArrayCells(address="B3", size=3, elementMerged=true)
6 private List<String> words;
7
8}
3.5.3. 書き込み時に配列・リストのサイズが不足、または余分である場合
アノテーション @XlsArrayOption を指定することで、書き込み時のセルの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が小さく、足りない場合の操作を指定します。属性
remainedOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が大きく、余っている場合の操作を指定します。
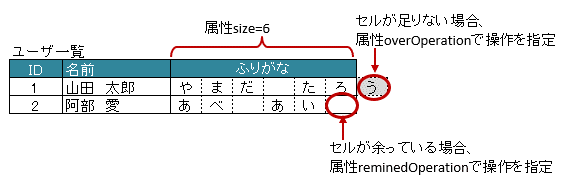
図 - 3.5.4 ArrayCells(ArrayOption)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsArrayCells(address="B3", size=6)
5 @XlsArrayOption(overOperation=OverOperation.Error, remainedOperation=RemainedOperation.Clear)
6 private List<String> nameKana;
7}
3.5.4. 位置情報/見出し情報を取得する際の注意事項
マッピング対象のセルのアドレスを取得する際に、フィールド Map<String, Point> positions を定義しておけば、自動的にアドレスがマッピングされます。
通常は、キーにはプロパティ名が記述(フィールドの場合はフィールド名)が入ります。
アノテーション @XlsArrayCells でマッピングしたセルのキーは、 <プロパティ名>[<インデックス>] の形式になります。
インデックスは、0から始まります。
マッピング対象の見出しを取得する、フィールド Map<String, String> labels は、見出しはないため取得することはできません。
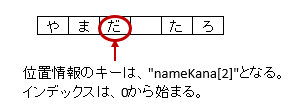
図 - 3.5.5 XlsArrayCells(positions/labels)
1public class SampleRecord {
2
3 // 位置情報
4 private Map<String, Point> positions;
5
6 // 見出し情報
7 private Map<String, String> labels;
8
9 @XlsArrayCells(address="B3", size=6)
10 private List<String> nameKana;
11}
12
13// 位置情報・見出し情報へのアクセス
14SampleRecord record = /* レコードのインスタンスの取得 */;
15
16Point position = record.positions.get("nameKana[2]");
17
18// 見出しは存在しないので、nullが返される
19String label = recrod.labeles.get("nameKana[2]");
3.6. @XlsLabelledArrayCells
セルの見出し用のラベルセルを指定し、左右もしくは下側に連続し隣接するセルをCollection(List, Set)または配列にマッピングします。 [ver.2.0+]
@XlsArrayCells と @XlsLabelledCell を融合したアノテーションとなります。
属性
labelで、見出しとなるセルの値を指定します。属性
typeで、見出しセルから見て値が設定されている位置を指定します。列挙型
LabelledCellTypeで、左右もしくは下側のセルを指定できます。
属性
directionで、連続する隣接するセルの方向を指定します。列挙型
ArrayDirectionで、横方向(右方向)もしくは、直方向(下方向)を指定できます。初期値は、横方向(右方向)です。
ただし、セルの位置を左側(
type=LabelledCellType.Left)とした場合、セルの方向は横方向(direction=ArrayDirection.Horizon) は、設定できないため注意してください。
属性
sizeで、連続するセルの個数を指定します。属性
optionalで、見出しとなるセルが見つからない場合に無視するかどうかを指定しできます。Collection(List, Set)型または配列のフィールドに付与します。
List型などの場合、Genericsのタイプとして、マッピング先のクラスを指定します。
指定しない場合は、アノテーションの属性
elementClassでクラス型を指定します。
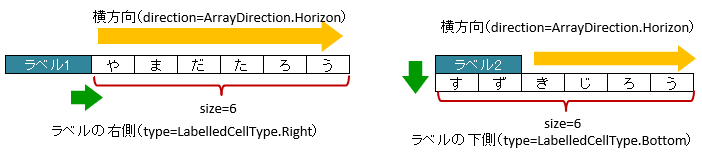
図 - 3.6.1 LabelledArrayCells
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // ラベルの右側 + 横方向の隣接するセル
5 // 属性directionを省略した場合は、ArrayDirection.Horizonを指定したと同じ意味。
6 @XlsLabelledArrayCells(label="ラベル1", type=LabelledCellType.Right, size=6)
7 private List<String> nameKanas1;
8
9 // ラベルの下側 + 横方向の隣接するセル
10 // 属性optional=trueと設定すると、ラベルセルが見つからなくても処理を続行する
11 @XlsLabelledArrayCells(label="ラベル2", type=LabelledCellType.Bottom,
12 direction=ArrayDirection.Horizon, size=6, optional=true)
13 private String[] nameKanas2;
14
15}
3.6.1. 縦方向に隣接したセルをマッピングする場合
縦方向にマッピングするため、属性
directionを、ArrayDirection.Verticalに設定します。
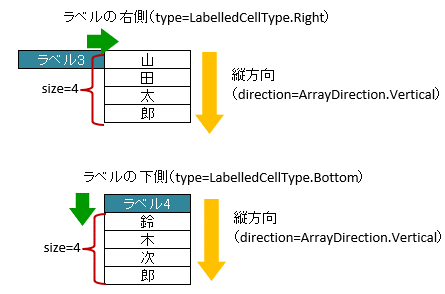
図 - 3.6.2 LabelledArrayCells(direction)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // ラベルの右側 + 縦方向の隣接するセル
5 // 属性direction=ArrayDirection.Verticalを指定すると、縦方向にマッピングします。
6 @XlsLabelledArrayCells(label="ラベル3", type=LabelledCellType.Right,
7 direction=ArrayDirection.Vertical, size=4)
8 private List<String> nameKanas3;
9
10 // ラベルの下側 + 縦方向の隣接するセル
11 @XlsLabelledArrayCells(label="ラベル4", type=LabelledCellType.Right,
12 direction=ArrayDirection.Vertical, size=4)
13 private String[] nameKanas4 nameKanas4;
14}
3.6.2. ラベルセルから離れたセルを指定する方法(属性range)
属性 range を指定すると、属性typeの方向に向かって指定した セル数分を検索 し、最初に発見した空白以外のセルを開始位置としてマッピングします。
属性
rangeとskipを同時に指定した場合、まず、skip分セルを読み飛ばし、そこからrangeの範囲で空白以外のセルを検索します。属性
rangeは、 読み込み時のみ有効 です。書き込み時に指定しても無視されます。ラベルセルから離れたセルを指定する場合に使用します。
ただし、データセルが偶然空白のときは、マッピング対象のセルがずれるため、この属性を使用する場合は注意が必要です。
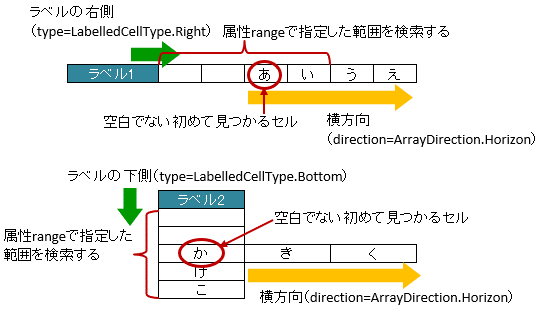
図 - 3.6.3 LabelledArrayCells(range)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledArrayCells(label="ラベル1", type=LabelledCellType.Right, range=4, size=4)
5 private List<String> words1;
6
7 @XlsLabelledArrayCells(label="ラベル2", type=LabelledCellType.Bottom, range=5, size=3)
8 private List<String> words2;
9
10}
3.6.3. ラベルセルから離れたセルを指定する方法(属性skip)
属性 skip を指定すると、属性typeの方向に向かって、ラベルセルから指定した セル数分離れた セルを開始位置としてマッピングします。
属性
rangeとskipを同時に指定した場合、まず、skip分セルを読み飛ばし、そこからrangeの範囲で空白以外のセルを検索します。
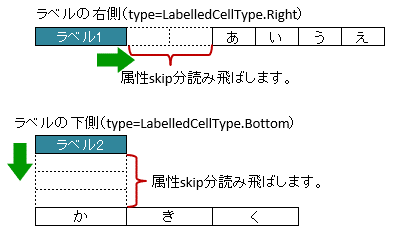
図 - 3.6.4 LabelledArrayCells(skip)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledArrayCells(label="ラベル1", type=LabelledCellType.Right, size=3, skip=2)
5 private List<String> words1;
6
7 @XlsLabelledArrayCells(label="ラベル2", type=LabelledCellType.Bottom, size=3, skip=3)
8 private List<String> words2;
9}
3.6.4. 重複するラベルを指定する場合
同じラベルのセルが複数ある場合は、区別するため見出しを属性 headerLabel で指定します。
属性headerLabelで指定したセルから、label属性で指定したセルを下方向に検索し、最初に見つかった一致するセルをラベルセルとして使用します。

図 - 3.6.5 LabelledArrayCells(headerLabel)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledArrayCells(label="ふりがな", type=LabelledCellType.Right, size=10
5 headerLabel="氏名")
6 private List<String> nameRuby;
7
8 @XlsLabelledArrayCells(label="ふりがな", type=LabelledCellType.Right, size=10
9 headerLabel="住所")
10 private List<String> addressRuby;
11
12}
3.6.5. ラベルセルが結合している場合(属性labelMerged)
属性
labelMergedで、見出しのラベルセルが結合を考慮するか指定します。trueのときは、結合されているセルを1つのラベルセルとしてマッピングします。
falseの場合は、結合されていても解除した状態と同じマッピング結果となります。
初期値はtrueであるため、特に意識はする必要はありません。
属性
labelMergedの値がfalseのとき、ラベルセルが結合されていると、値が設定されているデータセルまでの距離が変わるため、属性skipを併用します。
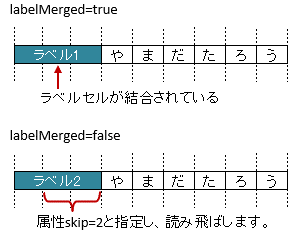
図 - 3.6.6 LabelledArrayCells(labelMerged)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // labelMerged=trueは初期値なので、省略可
5 @XlsLabelledArrayCells(label="ラベル1", type=LabelledCellType.Right, size=6)
6 private List<String> name1;
7
8 // labelMerged=falseで、ラベルが結合しているときは、skip属性を併用します。
9 @XlsLabelledArrayCells(label="ラベル2", type=LabelledCellType.Right, size=6,
10 labelMerged=false, skip=2)
11 private List<String> name2;
12
13}
3.6.6. 結合したセルをマッピングする場合(属性elementMerged)
属性
elementMergedで、セルの結合を考慮するか指定します。trueのときは、結合されているセルを1つのセルとしてマッピングします。
falseの場合は、結合されていても解除した状態と同じマッピング結果となります。
ただし、falseのときは、書き込む際には結合が解除されます。
初期値はtrueであるため、特に意識はする必要はありません。
セルが結合されている場合は、結合後の個数を指定します。
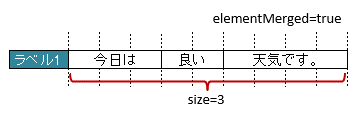
図 - 3.6.7 LabelledArrayCells(elementMerged)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // elementMerged=trueは初期値なので、省略可
5 @XlsLabelledArrayCells(label="ラベル1", type=LabelledCellType.Right, size=3,
6 elementMerged=true)
7 private List<String> words;
8
9}
3.6.7. 書き込み時に配列・リストのサイズが不足、または余分である場合
アノテーション @XlsArrayOption を指定することで、書き込み時のセルの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が小さく、足りない場合の操作を指定します。属性
remainedOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が大きく、余っている場合の操作を指定します。
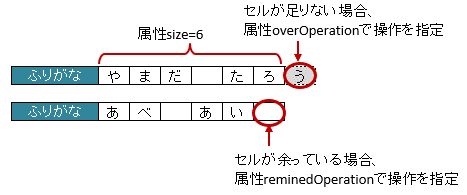
図 - 3.6.8 LabelledArrayCells(ArrayOption)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledArrayCells(label="ふりがな", type=LabelledCellType.Right, size=6)
5 @XlsArrayOption(overOperation=OverOperation.Error, remainedOperation=RemainedOperation.Clear)
6 private List<String> nameKana;
7
8}
3.6.8. 位置情報/見出し情報を取得する際の注意事項
マッピング対象のセルのアドレスを取得する際に、フィールド Map<String, Point> positions を定義しておけば、自動的にアドレスがマッピングされます。
通常は、キーにはプロパティ名が記述(フィールドの場合はフィールド名)が入ります。
アノテーション @XlsLabelledArrayCells でマッピングしたセルのキーは、 <プロパティ名>[<インデックス>] の形式になります。
インデックスは、0から始まります。
同様に、マッピング対象の見出しを取得する、フィールド Map<String, String> labels へのアクセスも、キーは、 <プロパティ名>[<インデックス>] の形式になります。
ただし、見出し情報の場合は、全ての要素が同じ値になるため、従来通りの <プロパティ名> でも取得できます。
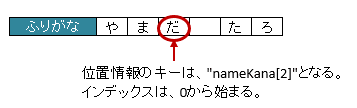
図 - 3.6.9 LabelledArrayCells(positions/labels)
1public class SampleRecord {
2
3 // 位置情報
4 private Map<String, Point> positions;
5
6 // 見出し情報
7 private Map<String, String> labels;
8
9 @XlsLabelledArrayCells(label="ふりがな", type=LabelledCellType.Right, size=6)
10 private List<String> nameKana;
11
12}
13
14// 位置情報・見出し情報へのアクセス
15SampleRecord record = /* レコードのインスタンスの取得 */;
16
17Point position = record.positions.get("nameKana[2]");
18
19String label = recrod.labeles.get("nameKana[2]");
20
21// 見出し情報の場合、従来通りのインデックスなしでも取得できる
22String label = recrod.labeles.get("nameKana");
3.6.9. ラベルセルを正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し、正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、label , headerLabel です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// シート用クラス
8@XlsSheet(name="Users")
9public class SampleSheet {
10
11 // 正規表現による指定
12 @XlsLabelledArrayCells(label="/名前.+/", type=LabelledCellType.Right, size=10)
13 private List<String> names;
14
15}
3.7. @XlsHorizontalRecords
水平方向に連続する行をCollection(List、Set)または配列にマッピングします。
標準では表には最上部に表の名称と列名を記述した行が必要になります。

図 - 3.7.1 HorizontalRecords
シート用クラスに、アノテーション @XlsHorizontalRecords 使って定義し、属性tableLabelで表の名称を指定します。
Colelction(List, Set)型または配列のフィールドに付与します。
List型などの場合、Genericsのタイプとして、マッピング先のBeanクラスを指定します。
指定しない場合は、アノテーションの属性 recordClass でクラス型を指定します。
レコード用クラスは、列の定義をアノテーション @XlsColumn や @XlsMapColumns で指定します。 また、ツリー構造のように入れ子になったレコードをマッピングする場合は、 @XlsNestedRecords を使用します。
1// シート用クラス
2@XlsSheet(name="Users")
3public class SampleSheet {
4
5 // 通常は、Genericsでクラス型を指定します。
6 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
7 private List<UserRecord> records;
8
9 // Generics型を使用しない場合は、属性 recordClass で指定します。
10 @XlsHorizontalRecords(tableLabel="ユーザ一覧", recordClass=UserRecord.class)
11 private List record2;
12}
13
14// レコード用クラス
15public class UserRecord {
16
17 @XlsColumn(columnName="ID")
18 private int id;
19
20 @XlsColumn(columnName="名前")
21 private String name;
22
23}
注釈
ver1.0から、Collection型(List型、Set型)にも対応しています。
インタフェースの型を指定する場合、次の実装クラスのインスタンスが設定されます。
List型の場合、
java.util.ArrayListクラス。Set型の場合、
java.util.LinkedHashSetクラス。Collection型の場合、
java.util.ArrayListクラス。
実装クラスを指定した場合、そのインスタンスが設定されます。
3.7.1. 表の開始位置の指定(表の名称がない場合)
表の名称がない場合、表の開始位置をインデックスやアドレスで指定します。
属性
headerColumn、headerRowで表の開始位置をインデックスで指定します。headerColumnは列番号で、0から始まります。
headerRowは行番号で、0から始まります。
属性
headerAddressで、 'B3'のようにシートのアドレス形式で指定もできます。属性headerAddressを指定する場合は、headerColumn, headerRowは指定しないでください。
属性headerAddressの両方を指定した場合、headerAddressの値が優先されます。
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // インデックス形式で表の開始位置を指定する(値は0から開始します)
5 @XlsHorizontalRecords(headerColumn=0, headerRow=1)
6 private List<UserRecord> records1;
7
8 // アドレス形式で表の開始位置を指定する場合
9 @XlsHorizontalRecords(headerAddress="A2")
10 private List<UserRecord> records2;
11}
3.7.2. 表の名称から開始位置が離れた場所にある場合
表の名称が定義してあるセルの直後に表がなく離れている場合、属性 bottom で表の開始位置がどれだけ離れているか指定します。
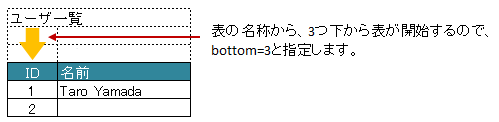
図 - 3.7.2 HorizontalRecords(bottom)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsHorizontalRecords(tableLabel="ユーザ一覧", bottom=3)
5 private List<UserRecord> records;
6
7}
3.7.3. 表の見出しが縦に結合されデータレコードの開始位置が離れた場所にある場合
表の見出しセルが縦に結合され、データレコードの開始位置が離れている場合、属性 headerBottom でデータレコードの開始位置がどれだけ離れているか指定します。 [ver1.1+]
下記の例の場合、見出しの「テスト結果」は横に結合されているため @XlsColumn(headerMerged=N) と組み合わせて利用します。
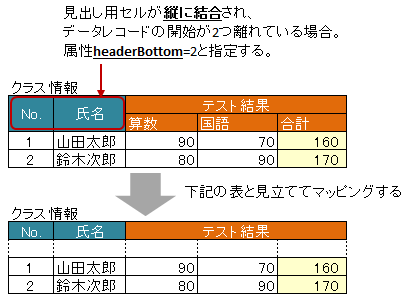
図 - 3.7.3 HorizontalRecords(headerBottom)
1// シート用クラス
2@XlsSheet(name="Users")
3public class SampleSheet {
4
5 // 見出しが縦に結合され、データのレコードの開始位置が離れている場合
6 @XlsHorizontalRecords(tableLabel="クラス情報", headerBottom=2)
7 private List<SampleRecord> records;
8
9}
10
11// レコード用クラス
12public class SampleRecord {
13
14 @XlsColumn(columnName="No.")
15 private int no;
16
17 @XlsColumn(columnName="名前")
18 private String name;
19
20 // セル「算数」のマッピング
21 @XlsColumn(columnName="テスト結果")
22 private int sansu;
23
24 // セル「国語」のマッピング
25 // 結合されている見出しから離れている数を指定する
26 @XlsColumn(columnName="テスト結果", headerMerged=1)
27 private int kokugo;
28
29 // セル「合計」のマッピング
30 // 結合されている見出しから離れている数を指定する
31 @XlsColumn(columnName="テスト結果", headerMerged=2)
32 private int sum;
33
34}
3.7.4. 表の終端の指定(属性terminal)
デフォルトでは行に1つもデータが存在しない場合、その表の終端となります。
行の一番左側の列の罫線によってテーブルの終端を検出する方法もあります。
この場合は @XlsHorizontalRecords の属性 terminal に RecordTerminal.Border を指定してください。
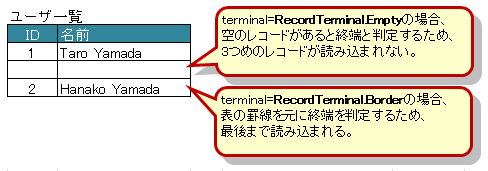
図 - 3.7.4 HorizontalRecords(terminal)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsHorizontalRecords(tableLabel="ユーザ一覧", terminal=RecordTerminal.Border)
5 private List<UserRecord> records;
6}
注釈
書き込む際にはテンプレート用の表中のセルは空と記述しているため、属性 terminal=RecordTermial.Empty を指定していると処理が終了してしまいます。
そのため、強制的に terminal=RecordTerminal.Border に補正して処理するようにしています。[ver0.5+]
3.7.5. 空のレコードを読み飛ばす条件の指定
レコード用のクラスには、レコードを宇読み飛ばすかどうか判定するためのメソッド用意し、アノテーション @XlsIgnorable を付与します。
また、この属性は読み込み時のみに有効です。書き込み時は、空のレコードでもそのまま出力されます。
1// ルートのオブジェクト
2@XlsSheet(name="シート名")
3public class SampleSheet {
4
5 @XlsHorizontalRecords(tableLabel="ユーザ一覧", terminal=RecordTerminal.Border)
6 private List<UserRecord> users;
7}
8
9// レコードのオブジェクト
10public class UserRecord {
11
12 @XlsColumn(columnName="名前")
13 private String name;
14
15 // レコードが空と判定するためのメソッド
16 @XlsIgnorable
17 public boolean isEmpty() {
18
19 if(name != null || !name.isEmpty()) {
20 return false;
21 }
22
23 return true;
24 }
25}
3.7.6. 表の終端の指定(属性terminateLabel)
表が他の表と連続しており属性terminalでBorder、Emptyのいずれを指定しても終端を検出できない場合があります。
このような場合は、属性 terminateLabel で終端を示すセルの文字列を指定します。

図 - 3.7.5 HorizontalRecords(terminateLabel)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsHorizontalRecords(tableLabel="クラス情報", terminal=RecordTerminal.Border,
5 terminateLabel="平均")
6 private List<UserRecord> userRecords;
7
8}
3.7.7. 表の見出しの走査の終了条件の指定(headerLimit)
属性 headerLimit を指定すると、テーブルのカラムが指定数見つかったタイミングでExcelシートの走査を終了します。
主に無駄な走査を抑制したい場合に指定します。
例えば、@XlsIterateTables において、 テーブルが隣接しており終端を検出できないときに、カラム数を明示的に指定してテーブルを区切りたい場合に使用します。
以下の例は、列の見出しセルを3つ分検出したところでそのテーブルの終端と見なします。
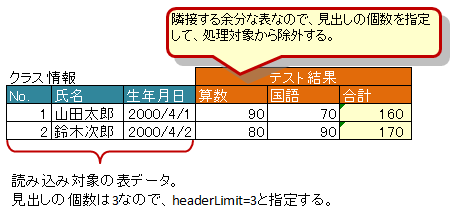
図 - 3.7.6 HorizontalRecords(headerLimit)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsHorizontalRecords(tableLabel="クラス情報", terminal=RecordTerminal.Border,
5 headerLimit=3)
6 private List<UserRecord> records;
7}
なお、セルが見つからなかった場合はエラーとなりますが、属性 optional にtrueを指定しておくと、無視して処理を続行します。
3.7.8. 表の見出しに空白がある場合(range)
表の走査は、まず指定したタイトルなどの表の開始位置を元に、見出し用セルを取得し、その後、データのレコードを取得します。
見出し用セルを取得する際には、右方向に向かって検索をしますが、 通常は空白セルが見つかった時点で走査を終了 します。
空白セルの次にも見出し用セルがあるような場合、属性 range を指定することで、指定した値分の空白セルを許容し、
さらに先のセルの検索を試みます。
また、属性 headerAddress や tableLabel で指定した位置から表が開始しないような場合も、
属性 range を指定することで、さらに先のセルの検索を試みます。
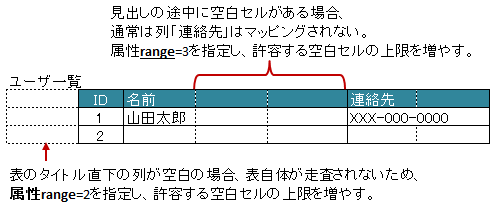
図 - 3.7.7 HorizontalRecords(range)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsHorizontalRecords(tableLabel="ユーザ一覧", terminal=RecordTerminal.Border,
5 range=3)
6 private List<UserRecord> records;
7}
3.7.9. 書き込み時にレコードが不足、余分である場合の操作の指定
アノテーション @XlsRecordOption を指定することで、書き込み時のレコードの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトのレコード数に対して、シートのレコード数が足りないときの操作を指定します。属性
remainedOperationで、書き込み時にJavaオブジェクトのレコード数に対して、シートのレコード数が余っているときの操作を指定します。
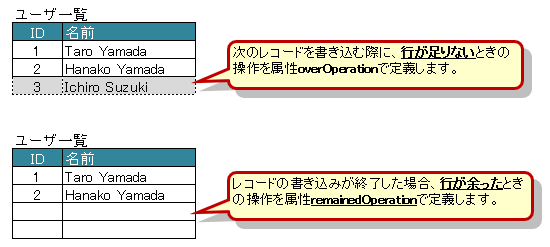
図 - 3.7.8 HorizontalRecords(RecordOption)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
5 @XlsRecordOption(overOperation=OverOperation.Insert, remainedOperation=RemainedOperation.Clear)
6 private List<UserRecord> records;
7
8}
3.7.10. 任意の位置からレコードが開始するかを指定する場合
データレコードの途中で中見出しがあり、分割されているような表の場合、アノテーション @XlsRecordFinder で、レコードの開始位置を決める処理を指定できます。 [ver2.0+]
属性
valueで、レコードの開始位置を検索する実装クラスを指定します。属性
argsで、レコードの開始位置を検索する実装クラスに渡す引数を指定します。
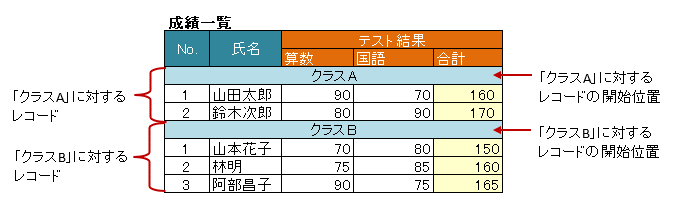
図 - 3.7.9 HorizontalRecords(RecordFinder)
1// マッピングの定義
2@XlsSheet(name="Users")
3public class SampleSheet {
4
5 @XlsOrder(1)
6 @XlsHorizontalRecords(tableLabel="成績一覧", bottom=2, terminal=RecordTerminal.Border, terminateLabel="/クラス.+/")
7 @XlsRecordFinder(value=ClassNameRecordFinder.class, args="クラスA")
8 private List<Record> classA;
9
10 @XlsOrder(2)
11 @XlsHorizontalRecords(tableLabel="成績一覧", bottom=2, terminal=RecordTerminal.Border, terminateLabel="/クラス.+/")
12 @XlsRecordFinder(value=ClassNameRecordFinder.class, args="クラスB")
13 private List<Record> classB;
14
15}
16
17// クラス用の見出しのレコードを探すクラス
18public class ClassNameRecordFinder implements RecordFinder {
19
20 @Override
21 public CellPosition find(ProcessCase processCase, String[] args, Sheet sheet,
22 CellPosition initAddress, Object beanObj, Configuration config) {
23
24 // 実装は省略
25 }
26
27}
3.7.11. 表の名称を正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、tableLabel , terminateLabel です。
さらに、レコードの列の見出し @XlsColumn も、この機能が有効になります。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// シート用クラス
8@XlsSheet(name="Users")
9public class SampleSheet {
10
11 // 正規表現による指定
12 @XlsHorizontalRecords(tableLabel="/ユーザ一覧.+/")
13 private List<UserRecord> records;
14
15}
3.8. @XlsVerticalRecords
垂直方向に連続する列をListまたは配列にマッピングします。 要するに @XlsHorizontalRecords を垂直方向にしたものです。
メソッドに定義する場合、@XlsHorizontalRecords と同じくList型の引数を1つだけ取るsetterメソッドに対して付与します。
ここでは、アノテーション @XlsHorizontalRecords と異なる部分を説明します。 共通の使い方は、アノテーション @XlsHorizontalRecords の説明を参照してください。

図 - 3.8.1 VerticalRecords
1// シート用クラス
2@XlsSheet(name="Weather")
3public class SampleSheet {
4
5 @XlsVerticalRecords(tableLabel="天気情報")
6 private List<WeatherRecord> records;
7
8}
9
10// レコード用クラス
11public class WeatherRecord {
12
13 @XlsColumn(columnName="時間")
14 private String time;
15
16 @XlsColumn(columnName="降水")
17 private double precipitation;
18}
3.8.1. 表の名称位置の指定
実際に表を作る場合、垂直方向ですが表の名称は上方に設定することが一般的です。
そのような場合、属性 tableLabelAbove の値を true に設定すると表のタイトルが上方に位置するとして処理します。 [ver1.0+]

図 - 3.8.2 VerticalRecords(tableLabelAbove)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsVerticalRecords(tableLabel="天気情報", tableLabelAbove=true)
5 private List<WeatherRecord> records;
6}
3.8.2. 表の名称から開始位置が離れた場所にある場合(right)
表の名称が定義してあるセルの直後に表がなく離れている場合、属性 right で表の開始位置が 右方向 にどれだけ離れているか指定します。 [ver1.0]+
アノテーション @XlsHorizontalRecords の属性 bottom と同じような意味になります。

図 - 3.8.3 VerticalRecords(right)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsVerticalRecords(tableLabel="天気情報", right=3)
5 private List<WeatherRecord> records;
6}
3.8.3. 表の名称から開始位置が離れた場所にある場合(bottom)
属性 tableLabelAbove の値が true のときのみ有効になります。
表の名称がセルの直後に表がなく離れている場合、属性 bottom で表の開始位置が 下方向 にどれだけ離れているか指定します。 [ver2.0]+
アノテーション @XlsHorizontalRecords の属性 bottom と同じような意味になります。
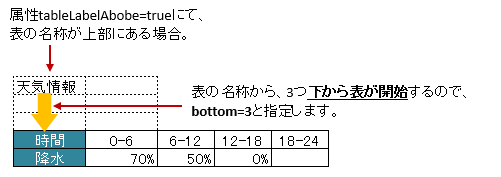
図 - 3.8.4 VerticalRecords(bottom)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsVerticalRecords(tableLabel="天気情報", tableLabelAbove=true, bottom=3)
5 private List<WeatherRecord> records;
6}
3.8.4. 表の見出しが横に結合されデータレコードの開始位置が離れた場所にある場合
表の見出しセルが横に結合され、データレコードの開始位置が離れている場合、属性 headerRight でデータレコードの開始位置がどれだけ離れているか指定します。 [ver1.1+]
アノテーション @XlsHorizontalRecords の属性 headerBottom と同じような意味になります。
下記の例の場合、見出しの「テスト結果」は横に結合されているため @XlsColumn(headerMerged=N) と組み合わせて利用します。

図 - 3.8.5 VerticalRecords(headerRight)
1// シート用クラス
2@XlsSheet(name="Weather")
3public class SampleSheet {
4
5 // 見出しが横に結合され、データのレコードの開始位置が離れている場合
6 @XlsVerticalRecords(tableLabel="天気情報", headerRight=2)
7 private List<WeatherRecord> records;
8
9}
10
11// レコード用クラス
12public class WeatherRecord {
13
14 @XlsColumn(columnName="時間")
15 private String time;
16
17 // セル「降水」のマッピング
18 @XlsColumn(columnName="測定結果")
19 private double precipitation;
20
21 // セル「気温」のマッピング
22 // 結合されている見出しから離れている数を指定する
23 @XlsColumn(columnName="測定結果", headerMerged=1)
24 private int temperature;
25
26 // セル「天気」のマッピング
27 // 結合されている見出しから離れている数を指定する
28 @XlsColumn(columnName="測定結果", headerMerged=2)
29 private String wather;
30
31}
3.8.5. 書き込み時にレコードが不足、余分である場合の操作の指定
アノテーション @XlsRecordOption を指定することで、書き込み時のレコードの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトのレコード数に対して、シートのレコード数が足りないときの操作を指定します。ただし、
@XlsVerticalRecordsの場合、列の挿入を行うOverOperation#Insertは使用できません。
属性
remainedOperationで、書き込み時にJavaオブジェクトのレコード数に対して、シートのレコード数が余っているときの操作を指定します。ただし、
@XlsVerticalRecordsの場合、列の削除を行うRemainedOperation#Deleteは使用できません。
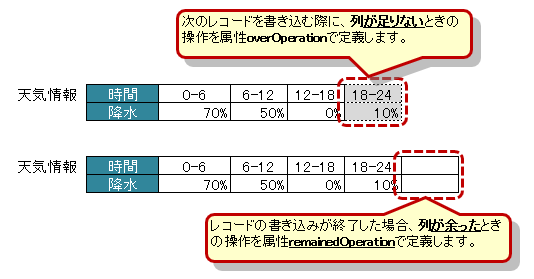
図 - 3.8.6 VerticalRecords(RecordOption)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsVerticalRecords(tableLabel="天気情報")
5 @XlsRecordOption(overOperation=OverOperation.Copy, remainedOperation=RemainedOperation.Clear)
6 private List<WeatherRecord> records;
7
8}
3.8.6. 任意の位置からレコードが開始するかを指定する場合
データレコードの途中で中見出しがあり、分割されているような表の場合、アノテーション @XlsRecordFinder で、レコードの開始位置を決める処理を指定できます。 [ver2.0+]
属性
valueで、レコードの開始位置を検索する実装クラスを指定します。属性
argsで、レコードの開始位置を検索する実装クラスに渡す引数を指定します。
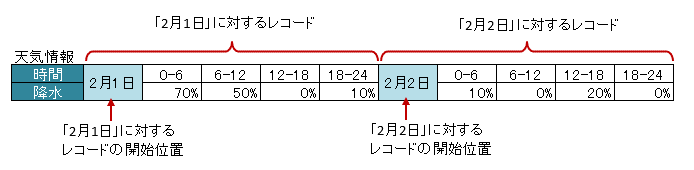
図 - 3.8.7 VerticalRecords(RecordFinder)
1// マッピングの定義
2@XlsSheet(name="Weather")
3public class SampleSheet {
4
5 @XlsOrder(1)
6 @XlsVerticalRecords(tableLabel="天気情報", tableLabelAbove=true, terminal=RecordTerminal.Border, terminateLabel="/{0-9}月{0-9}[1-2]日/")
7 @XlsRecordFinder(value=DateRecordFinder.class, args="2月1日")
8 private List<WeatherRecord> date1;
9
10 @XlsOrder(2)
11 @XlsVerticalRecords(tableLabel="天気情報", tableLabelAbove=true, terminal=RecordTerminal.Border, terminateLabel="/{0-9}月{0-9}[1-2]日/")
12 @XlsRecordFinder(value=DateRecordFinder.class, args="2月1日")
13 private List<WeatherRecord> date2;
14
15}
16
17// 日にち用の見出しのレコードを探すクラス
18public class DateRecordFinder implements RecordFinder {
19
20 @Override
21 public CellPosition find(ProcessCase processCase, String[] args, Sheet sheet,
22 CellPosition initAddress, Object beanObj, Configuration config) {
23
24 // 実装は省略
25 }
26
27}
3.9. @XlsColumn
アノテーション @XlsHorizontalRecords または @XlsVerticalRecords において、 1つのカラムをマッピングします。
属性
columnNameで、見出しとなるセルのラベルを指定します。セルが見つからない場合はエラーとなりますが、属性
optionalをtrueとすることで無視して処理を続行します。

図 - 3.9.1 Column
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")}
7 private String name;
8
9 // 存在しない列の場合は読み飛ばす
10 @XlsColumn(columnName="備考", optional=true)
11 private String name;
12}
3.9.1. データの列が結合されている場合
同じ値がグループごとに結合されているカラムの場合は属性 merged をtrueに設定します。
こうしておくと、前の列の値が引き継がれて設定されます。
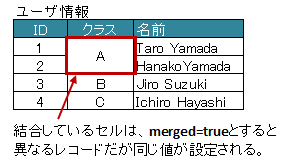
図 - 3.9.2 Column(merged)
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 // 結合されてる可能性がある列
7 @XlsColumn(columnName="クラス", merged=true)
8 private String className;
9
10 @XlsColumn(columnName="名前")
11 private String name;
12
13}
注釈
書き込みに時では、属性mergedの値が true であっても、上部または左側のセルと値が同じでも結合は基本的に行いません。
ただし、システム設定 Configuration の項目「mergeCellOnSave」の値をtrueにすると結合されます。
3.9.2. 見出し行が結合されている場合
見出し行が結合され、1つの見出しに対して複数の列が存在する場合は属性 headerMerged を使用します。
属性headerMergedの値には列見出しから何セル分離れているかを指定します。
属性columnNameで指定する見出しのセル名は、結合されているセルと同じ値を指定します。
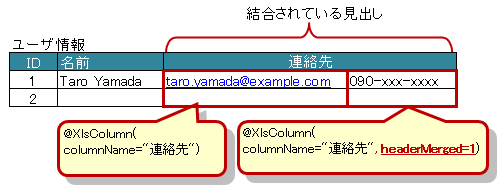
図 - 3.9.3 Column(headerMerged)
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 @XlsColumn(columnName="連絡先")
10 private String mailAddress;
11
12 // 結合されている見出しから離れている数を指定する
13 @XlsColumn(columnName="連絡先", headerMerged=1)
14 private String tel;
15
16}
3.9.3. 見出しを正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し、正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、columnName です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// レコード用クラス
8public class SampleRecord {
9
10 @XlsColumn(columnName="ID")
11 private int id;
12
13 // 正規表現による指定
14 @XlsColumn(columnName="/名前.+/")
15 private String name;
16
17}
3.10. @XlsMapColumns
アノテーション @XlsHorizontalRecords もしくは @XlsVerticalRecords において、
指定されたレコード用クラスのカラム数が可変の場合に、それらのカラムを java.util.Map として設定します。
BeanにはMapを引数に取るフィールドまたはメソッドを用意し、このアノテーションを記述します。
属性
previousColumnNameで、指定された次のカラム以降、カラム名をキーとしたMapが生成され、Beanにセットされます。属性
optionalで、見出しとなるセルが見つからない場合に無視するかどうかを指定しできます。 [ver2.0+]
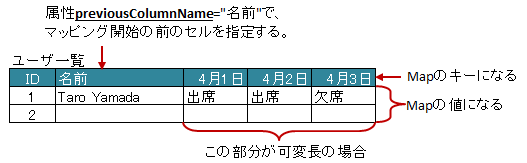
図 - 3.10.1 MapColumns
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 @XlsMapColumns(previousColumnName="名前")
10 private Map<String, String> attendedMap;
11}
3.10.1. 終了条件のセルを指定する場合
属性 nextColumnName で、指定した前のカラムまでが処理対象となり、マッピングの終了条件を指定できます。 [ver1.2+]
属性
optionalで、見出しとなるセルが見つからない場合に無視するかどうかを指定しできます。 [ver2.0+]
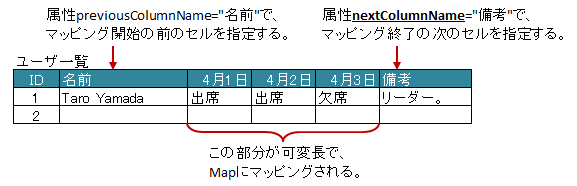
図 - 3.10.2 MapColumns(nextColumnName)
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 @XlsMapColumns(previousColumnName="名前", nextColumnName="備考")
10 private Map<String, String> attendedMap;
11
12 @XlsColumn(columnName="備考")
13 private String comment;
14
15}
3.10.2. 型変換する場合
アノテーション @XlsConverter などで型変換を適用するときは、Mapの値が変換対象となります。 マップのキーは必ずString型を指定してください。
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 // 型変換用のアノテーションを指定した場合、Mapの値に適用されます。
10 @XlsMapColumns(previousColumnName="名前")
11 @XlsBooleanConverter(loadForTrue={"出席"}, loadForFalse={"欠席"},
12 saveAsTrue="出席", saveAsFalse"欠席"
13 failToFalse=true)
14 private Map<String, Boolean> attendedMap;
15}
3.10.3. 位置情報/見出し情報を取得する際の注意事項
マッピング対象のセルのアドレスを取得する際に、フィールド Map<String, Point> positions を定義しておけば、自動的にアドレスがマッピングされます。
通常は、キーにはプロパティ名が記述(フィールドの場合はフィールド名)が入ります。
アノテーション @XlsMapColumns でマッピングしたセルのキーは、 <プロパティ名>[<セルの見出し>] の形式になります。
同様に、マッピング対象の見出しを取得する、フィールド Map<String, String> labels へのアクセスも、
キーは、 <プロパティ名>[<セルの見出し>] の形式になります。
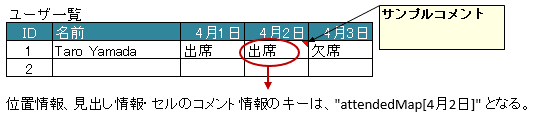
図 - 3.10.3 MapColumns(positions/labels)
1public class SampleRecord {
2
3 // 位置情報
4 private Map<String, Point> positions;
5
6 // 見出し情報
7 private Map<String, String> labels;
8
9 @XlsColumn(columnName="ID")
10 private int id;
11
12 @XlsColumn(columnName="名前")
13 private String name;
14
15 @XlsMapColumns(previousColumnName="名前")
16 private Map<String, String> attendedMap;
17}
18
19// 位置情報・見出し情報へのアクセス
20SampleRecord record = /* レコードのインスタンスの取得 */;
21
22Point position = record.positions.get("attendedMap[4月2日]");
23
24String label = recrod.labeles.get("attendedMap[4月2日]");
3.10.4. 見出しを正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し、正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、previousColumnName 、nextColumnName です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// レコード用クラス
8public class SampleRecord {
9
10 @XlsColumn(columnName="ID")
11 private int id;
12
13 // 正規表現による指定
14 @XlsColumn(columnName="/名前.+/")
15 private String name;
16
17 // 正規表現による指定
18 @XlsMapColumns(previousColumnName="/名前.+/", nextColumnName="/備考.+/")
19 private Map<String, String> attendedMap;
20
21 @XlsColumn(columnName="/備考.+/")
22 private String comment;
23
24}
3.10.5. 書き込み前に動的にテンプレートファイルを書き換える
書き込み処理の場合、マップのキーがデータごとに異なり、テンプレートのフォーマットと合わない場合があります。
そのような場合、テンプレートファイルを書き込むデータに合わせて書き換えます。
その際には、 ライフサイクル・コールバック用のアノテーション @XlsPreSave で、実装できます。
実装処理は、Apache POIのAPIを使って行います。
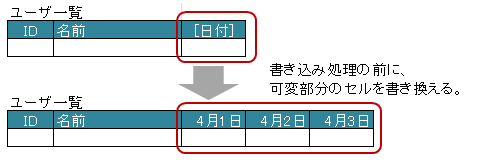
図 - 3.10.4 MapColumns(preSave)
1// シート用クラス
2@XlsSheet(name="List")
3public class SampleSheet {
4
5 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
6 @XlsRecordOption(overOperation=OverOperation.Insert)
7 List<SampleRecord> records;
8
9 // XlsMapColumnsのマッピング用のセルを作成する
10 @XlsPreSave
11 public void onPreSave(final Sheet sheet, final Configuration config) {
12
13 try {
14 final Workbook workbook = sheet.getWorkbook();
15
16 // 基準となる日付のセル[日付]を取得する
17 Cell baseHeaderCell = Utils.getCell(sheet, "[日付]", 0, 0, config);
18
19 // 書き換えるための見出しの値の取得
20 List<String> dateHeaders = new ArrayList<>(records.get(0).attendedMap.keySet());
21
22 // 1つ目の見出しの書き換え
23 baseHeaderCell.setCellValue(dateHeaders.get(0));
24
25 // 2つ目以降の見出し列の追加
26 Row headerRow = baseHeaderCell.getRow();
27 for(int i=1; i < dateHeaders.size(); i++) {
28 Cell headerCell = headerRow.createCell(baseHeaderCell.getColumnIndex() + i);
29
30 CellStyle style = workbook.createCellStyle();
31 style.cloneStyleFrom(baseHeaderCell.getCellStyle());
32 headerCell.setCellStyle(style);
33 headerCell.setCellValue(dateHeaders.get(i));
34
35 }
36
37 // 2つめ以降のデータ行の列の追加
38 Row valueRow = sheet.getRow(baseHeaderCell.getRowIndex() + 1);
39 Cell baseValueCell = valueRow.getCell(baseHeaderCell.getColumnIndex());
40 for(int i=1; + i < dateHeaders.size(); i++) {
41 Cell valueCell = valueRow.createCell(baseValueCell.getColumnIndex() + i);
42
43 CellStyle style = workbook.createCellStyle();
44 style.cloneStyleFrom(baseValueCell.getCellStyle());
45 valueCell.setCellStyle(style);
46
47 }
48
49 } catch (Exception e) {
50 throw new RuntimeException(e);
51 }
52
53 }
54
55}
56
57// レコード用クラス
58public class SampleRecord {
59
60 @XlsColumn(columnName="ID")
61 private int id;
62
63 @XlsColumn(columnName="名前")
64 private String name;
65
66 // 可変長のセルのマッピング
67 @XlsMapColumns(previousColumnName="名前")
68 private Map<String, String> attendedMap;
69
70}
3.11. @XlsArrayColumns
アノテーション @XlsHorizontalRecords もしくは @XlsVerticalRecords において、 隣接する連続したカラムを、Collection(List, Set)または配列にマッピングします。 [ver.2.0+]
属性
columnNameで、見出しとなるセルのラベルを指定します。属性
sizeで、連続するセルの個数を指定します。見出しとなるカラムは、結合している必要があります。
見出しとなるセルが見つからない場合はエラーとなりますが、属性
optionalをtrueとすることで無視して処理を続行します。Collection(List, Set)型または配列のフィールドに付与します。
List型などの場合、Genericsのタイプとして、マッピング先のクラスを指定します。
指定しない場合は、アノテーションの属性
elementClassでクラス型を指定します。

図 - 3.11.1 ArrayColumns
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 @XlsArrayColumns(columnName="ふりがな", size=10)
10 private List<String> nameRuby;
11}
3.11.1. 結合したセルをマッピングする場合
属性
elementMergedで、セルの結合を考慮するか指定します。trueのときは、結合されているセルを1つのセルとしてマッピングします。
falseの場合は、結合されていても解除した状態と同じマッピング結果となります。
ただし、falseのときは、書き込む際には結合が解除されます。
初期値はtrueであるため、特に意識はする必要はありません。
セルが結合されている場合は、結合後の個数を指定します。
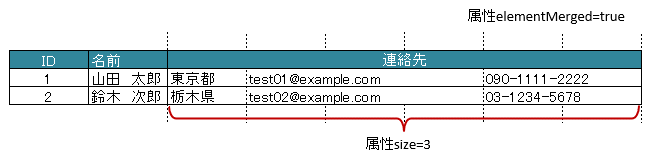
図 - 3.11.2 ArrayColumns(elementMerged)
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 // elementMerged=trueは初期値なので、省略可
10 @XlsArrayColumns(columnName="連絡先", size=3)
11 private List<String> contactInfos;
12}
3.11.2. 書き込み時に配列・リストのサイズが不足、または余分である場合
アノテーション @XlsArrayOption を指定することで、書き込み時のセルの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が小さく、足りない場合の操作を指定します。属性
remainedOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が大きく、余っている場合の操作を指定します。
図 - 3.11.3 ArrayColumns(ArrayOption)
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private int id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8
9 @XlsArrayColumns(columnName="ふりがな", size=6)
10 @XlsArrayOption(overOperation=OverOperation.Error, remainedOperation=RemainedOperation.Clear)
11 private List<String> nameRuby;
12}
3.11.3. 位置情報/見出し情報を取得する際の注意事項
マッピング対象のセルのアドレスを取得する際に、フィールド Map<String, Point> positions を定義しておけば、自動的にアドレスがマッピングされます。
通常は、キーにはプロパティ名が記述(フィールドの場合はフィールド名)が入ります。
アノテーション @XlsArrayColumns でマッピングしたセルのキーは、インデックス付きの <プロパティ名>[<インデックス>] 形式になります。
インデックスは、0から始まります。
同様に、マッピング対象の見出しを取得する、フィールド Map<String, String> labels へのアクセスも、キーは、 <プロパティ名>[<インデックス>] の形式になります。
ただし、見出し情報の場合は、全ての要素が同じ値になるため、従来通りの <プロパティ名> でも取得できます。
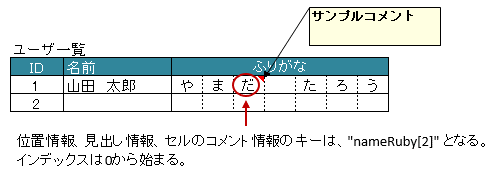
図 - 3.11.4 ArrayColumns(positions/labels)
1public class SampleRecord {
2
3 // 位置情報
4 private Map<String, Point> positions;
5
6 // 見出し情報
7 private Map<String, String> labels;
8
9 @XlsColumn(columnName="ID")
10 private int id;
11
12 @XlsColumn(columnName="名前")
13 private String name;
14
15 @XlsArrayColumns(columnName="ふりがな", size=6)
16 private List<String> nameRuby;
17}
18
19// 位置情報・見出し情報へのアクセス
20SampleRecord record = /* レコードのインスタンスの取得 */;
21
22Point position = record.positions.get("nameRuby[2]");
23
24String label = recrod.labeles.get("nameRuby[2]");
25
26// 見出し情報の場合、従来通りのインデックスなしでも取得できる
27String label = recrod.labeles.get("nameRuby");
3.11.4. 見出しを正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し、正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、columnName です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// レコード用クラス
8public class SampleRecord {
9
10 @XlsColumn(columnName="ID")
11 private int id;
12
13 // 正規表現による指定
14 @XlsColumn(columnName="/名前.+/")
15 private String name;
16
17 // 正規表現による指定
18 @XlsArrayColumns(columnName="/ふりがな.+/", size=10)
19 private List<String> nameRuby;
20
21
22}
3.12. @XlsNestedRecords
アノテーション @XlsHorizontalRecords もしくは @XlsVerticalRecords のレコード用クラスにおいて、ツリー構造のように入れ子になっている表をマッピングする際に使用します。 [ver.1.4+]
3.12.1. 一対多の関係
一対多の関係を表現する際には、Collection(List/Set)または、配列で指定します。
親子関係は、結合しているかで表現します。
結合している個数が不一致の場合は、例外
NestedRecordMergedSizeExceptionがスローされます。
親に指定しているJavaBeanクラスは、子や孫には指定することができません。
カラムの定義はレコードに記述されているため、親子に同じレコードのクラス定義があると、無限に再帰処理してしまうため、それを防ぐための制約になります。
属性
@XlsHorizotanlRecords#terminalLabelの終端の判定は、入れ子になったレコードごとに判定されます。読み込みの際、アノテーション @XlsIgnorable で、空のレコードを読み飛ばした結果、レコード数が0件となった場合は、要素数0個リストや配列が設定されます。
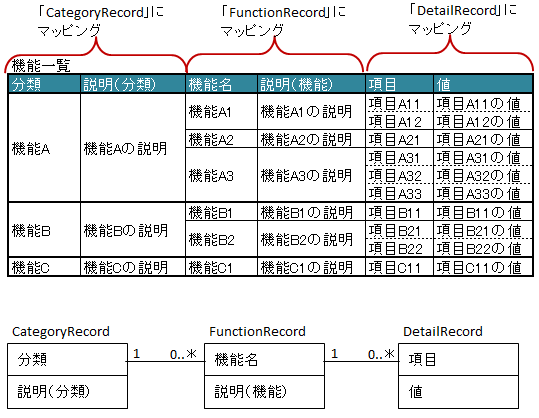
図 - 3.12.1 NestedRecords(一対多の関係)
1// シート用クラス
2@XlsSheet(name="機能")
3public class SampleSheet {
4
5 @XlsHorizontalRecords(tableLabel="機能一覧")
6 private List<CategoryRecord> categories;
7
8}
9
10// レコード用クラス(分類)
11public class CategoryRecord {
12
13 @XlsColumn(columnName="分類")
14 private String name;
15
16 @XlsColumn(columnName="説明(分類)")
17 private String description;
18
19 // ネストしたレコードのマッピング
20 @XlsNestedRecords
21 private List<FunctionRecord> functions;
22
23}
24
25// レコード用クラス(機能)
26public class FunctionRecord {
27
28 @XlsColumn(columnName="機能名")
29 private String name;
30
31 @XlsColumn(columnName="説明(機能)")
32 private String description;
33
34 // ネストしたレコードのマッピング
35 @XlsNestedRecords
36 private List<DetailRecord> details;
37
38}
39
40// レコード用クラス(詳細)
41public class DetailRecord {
42
43 @XlsColumn(columnName="項目")
44 private String name;
45
46 @XlsColumn(columnName="値")
47 private String value;
48
49}
3.12.2. 一対一の関係
一対一の関係をマッピングする際には、ネストしたクラスを直接指定します。
クラス定義などの制約は、基本的に一対多のときと同じです。

図 - 3.12.2 NestedRecords(一対一の関係)
1// シート用クラス
2@XlsSheet(name="学期末テスト")
3public class SampleSheet {
4
5 @XlsHorizontalRecords(tableLabel="テスト結果", bottom=2)
6 private List<UserRecord> users;
7
8}
9
10// レコード用クラス(生徒情報)
11public class UserRecord {
12
13 @XlsColumn(columnName="No.")
14 private int no;
15
16 @XlsColumn(columnName="クラス", merged=true)
17 private String className;
18
19 @XlsColumn(columnName="氏名")
20 private String name;
21
22 // ネストしたレコードのマッピング
23 @XlsNestedRecords
24 private ResultRecord result;
25
26}
27
28// レコード用クラス(テスト結果)
29public class ResultRecord {
30
31 @XlsColumn(columnName="国語")
32 private int kokugo;
33
34 @XlsColumn(columnName="算数")
35 private int sansu;
36
37 @XlsColumn(columnName="合計")
38 private int sum;
39
40}
3.13. @XlsIterateTables
同一の構造の表がシート内で繰り返し出現する場合に使用し、Collection(List、Set)または配列にマッピングします。 次のアノテーションを組み合わせて構成します。
横方向の表をマッピングするアノテーション @XlsHorizontalRecords 。
縦方向の表をマッピングするアノテーション @XlsVerticalRecords [ver.2.0+] 。
ただし、アノテーション
@XlsHorizontalRecordsと同時に使用はできません。
見出し付きの1つのセルをマッピングするアノテーション @XlsLabelledCell 。
見出し付きの連続し隣接する複数のセルをマッピングするアノテーション @XlsLabelledArrayCells [ver.2.0+]。
3.13.1. 基本的な使い方
属性 tableLabel で繰り返し部分の表の名称を指定します。
また、属性bottomは、@XlsIterateTables 内で @XlsHorizontalRecords を使用する場合に、テーブルの開始位置が @XlsIterateTables の表の名称セルからどれだけ離れているかを指定します。
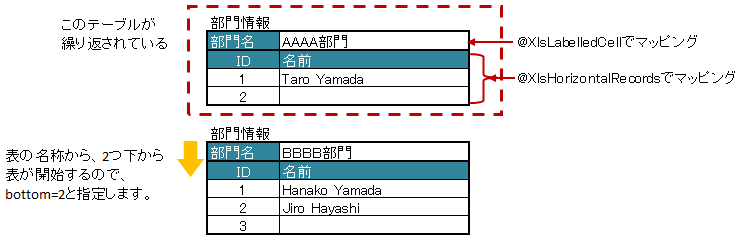
図 - 3.13.1 IterateTables
1@XlsSheet(name="シート名")
2public class SampleSheet {
3
4 @XlsIterateTables(tableLabel="部門情報", bottom=2)
5 private List<SampleTable> tables;
6}
繰り返し部分に対応するJavaBeanでは以下のように、アノテーション @XlsLabelledCell @XlsHorizontalRecords を使用できます。
アノテーション @XlsHorizontalRecords を使用する場合、属性tableLabel は設定する必要はありません。
@XlsIterateTables の属性 tableLabelとbottomの値を引き継ぐため、指定しなくても問題ないためです。
1public class SampleTable {
2
3 @XlsLabelledCell(label="部門名", type=LabelledCellType.Right)
4 private String deptName;
5
6 @XlsHorizontalRecords(terminal=RecordTerminal.Border)
7 private List<SampleRecord> records;
8}
繰り返し部分に対応するJavaBeanで @XlsHorizontalRecords を使用した場合、通常の場合と同じく @XlsColumn や @XlsMapColumns で列とのマッピングを行います。
1public class SampleRecord {
2
3 @XlsColumn(columnName="ID")
4 private String id;
5
6 @XlsColumn(columnName="名前")
7 private String name;
8}
注釈
ver.2.0から、Collection型(List型、Set型)にも対応しています。
インタフェースの型を指定する場合、次の実装クラスのインスタンスが設定されます。
List型の場合、
java.util.ArrayListクラス。Set型の場合、
java.util.LinkedHashSetクラス。Collection型の場合、
java.util.ArrayListクラス。
実装クラスを指定した場合、そのインスタンスが設定されます。
3.13.2. 縦方向の表を組み合わせてマッピングする場合
縦方向の表をマッピングするアノテーション @XlsVerticalRecords も使用できます。
ただし、横方向の表をマッピングするアノテーション
@XlsHorizontalRecordsと同時に使用することはできません。属性
tableLabelAbove=trueが自動的に有効になり、表の見出しが上部にあることを前提に処理されます。

図 - 3.13.2 IterateTables(縦方向)
1// シート用クラス
2@XlsSheet(name="観測データ")
3public class SampleSheet {
4
5 @XlsIterateTables(tableLabel="/観測情報.+/", bottom=2)
6 private List<DataTable> tables;
7}
8
9// テーブル用クラス
10public class DataTable {
11
12 @XlsLabelledCell(label="日付", type=LabelledCellType.Right)
13 private LocalDate date;
14
15 @XlsVerticalRecords(terminal=RecordTerminal.Border)
16 private List<WeatherRecord> records;
17}
18
19// レコード用クラス
20public class WeatherRecord {
21
22 @XlsColumn(columnName="時間")
23 private String time;
24
25 @XlsColumn(columnName="降水")
26 private double precipitation;
27}
3.13.3. 表の名称を正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。 [ver1.1+]
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、tableLabel です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// シート用クラス
8@XlsSheet(name="シート名")
9public class SampleSheet {
10
11 // 正規表現による指定
12 @XlsIterateTables(tableLabel="/部門情報.+/", bottom=2)
13 private List<SampleTable> tables;
14
15}
3.14. @XlsComment
セルの列と行を指定して、セルのコメント情報をBeanのプロパティにマッピングします。 [ver.2.1+]
フィールドまたはメソッドに対して付与します。
書込み時のコメントの書式の制御は、アノテーション @XlsCommentOption で指定します。
属性
column、rowで、インデックスを指定します。columnは列番号で、0から始まります。
rowは行番号で、0から始まります。
属性
addressで、 'B3' のようにシートのアドレス形式で指定もできます。属性addressを指定する場合は、column, rowは指定しないでください。
属性addressの両方を指定した場合、addressの値が優先されます。
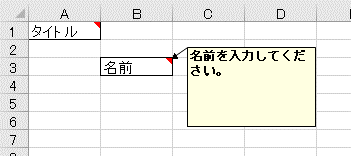
図 - 3.14.1 Comment
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // インデックス形式で指定する場合
5 @XlsComment(column=0, row=0)
6 private String titleComment;
7
8 // アドレス形式で指定する場合
9 @XlsComment(address="B3")
10 private String titleComment;
11
12}
3.15. @XlsLabelledComment
セルの見出し用のラベルセルを指定し、セルのコメントをマッピングします。 [ver.2.1+]
フィールドまたはメソッドに対して付与します。
書込み時のコメントの書式の制御は、アノテーション @XlsCommentOption で指定します。
属性
labelで、見出しとなるセルの値を指定します。属性
optionalで、見出しとなるセルが見つからない場合に無視するかどうかを指定しできます。

図 - 3.15.1 LabelledComment
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledComment(label="ラベル1")
5 private String titleComment;
6
7 // ラベルセルが見つからなくても処理を続行する
8 @XlsLabelledComment(label="ラベル2"optional=true)
9 private String summaryComment;
10}
3.15.1. ラベルセルが重複するセルを指定する方法
同じラベルのセルが複数ある場合は、区別するための見出しを属性 headerLabel で指定します。
属性headerLabelで指定したセルから、label属性で指定したセルを下方向に検索し、最初に見つかった一致するセルをラベルセルとして使用します。
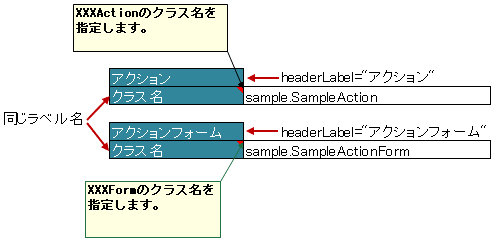
図 - 3.15.2 LabelledComment(headerLabel)
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 @XlsLabelledComment(label="クラス名", type=LabelledCellType.Right,
5 headerLabel="アクション")
6 private String actionClassNameComment;
7
8 @XlsLabelledComment(label="クラス名", type=LabelledCellType.Right,
9 headerLabel="アクションフォーム")
10 private String formClassNameComment;
11
12}
3.15.2. ラベルセルを正規表現、正規化して指定する場合
シートの構造は同じだが、ラベルのセルが微妙に異なる場合、ラベルセルを正規表現による指定が可能です。 また、空白や改行を除去してラベルセルを比較するように設定することも可能です。
正規表現で指定する場合、アノテーションの属性の値を
/正規表現/のように、スラッシュで囲み指定します。スラッシュで囲まない場合、通常の文字列として処理されます。
正規表現の指定機能を有効にするには、システム設定のプロパティ
regexLabelTextの値を trueに設定します。
ラベセルの値に改行が空白が入っている場合、それらを除去し、正規化してアノテーションの属性値と比較することが可能です。
正規化とは、空白、改行、タブを除去することを指します。
ラベルを正規化する機能を有効にするには、システム設定のプロパティ
normalizeLabelTextの値を trueに設定します。
これらの指定が可能な属性は、label , headerLabel です。
1// システム設定
2XlsMapper xlsMapper = new XlsMapper();
3xlsMapper.getConfiguration()
4 .setRegexLabelText(true) // ラベルを正規表現で指定可能にする機能を有効にする。
5 .setNormalizeLabelText(true); // ラベルを正規化して比較する機能を有効にする。
6
7// シート用クラス
8@XlsSheet(name="Users")
9public class SampleSheet {
10
11 // 正規表現による指定
12 @XlsLabelledComment(label="/名前.+/")
13 private String classNameComment;
14
15}
3.16. @XlsOrder
書き込み時に、@XlsHoriontalRecords を使用して行の挿入や削除する設定している場合、フィールドの処理順序によって、Map<String, Point> positions フィールドで座標が、ずれる場合があります。
このようなときに、@XlsOrder の属性 value で書き込む処理順序を指定し一定に保つことができます。
属性 value はJavaの仕様により省略が可能です。
@XlsOrder を付与しないフィールドは、付与しているフィールドよりも後から処理が実行されます。
属性valueが同じ値を設定されているときは、 フィールド名の昇順で優先度を決めて処理されます。
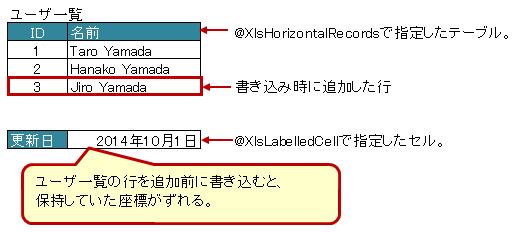
図 - 3.16.1 Order
1@XlsSheet(name="Users")
2public class SampleSheet {
3
4 // セルの位置情報
5 private Map<String, Point> positions;
6
7 @XlsOrder(order=1)
8 @XlsHorizontalRecords(tableLabel="ユーザ一覧", terminal=RecordTerminal.Border)
9 @XlsRecordOption(overOperation=OverOperation.Insert, remainedOperation=RemainedOperation.Delete)
10 private List<UserRecord> records;
11
12 // 属性valueは省略が可能
13 @XlsOrder(2)
14 @XlsLabelledCell(label="更新日", type=LabelledCellType.Right)
15 private Date updateTime;
16
17}
注釈
ソースコード上で定義したフィールドやメソッドの記述順は、実行時には保証されないため、@XlsOrder で順番を指定し、処理順序を一定にできます。
@XlsOrder を付与すると、書き込み時だけでなく読み込み時にも処理順序が一定になります。
3.17. @XlsIgnorable
アノテーション @XlsHorizontalRecords 、@XlsVerticalRecords を使用して、読み込む際に、空のレコードを読み飛ばしたい場合、 レコードが空と判定するためのメソッドに付与します。
@XlsIgnorableを付与したメソッドは、publicかつ引数なしの戻り値がboolean型の書式にする必要があります。@XlsVerticalRecords でも同様に使用できます。
また、この機能は読み込み時のみに有効です。書き込み時は、空のレコードでもそのまま出力されます。
1// ルートのオブジェクト
2@XlsSheet(name="シート名")
3public class UnitUser {
4
5 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
6 private List<User> users;
7
8}
9
10// レコードのオブジェクト
11public class User {
12
13 @XlsColumn(columnName="No.")
14 private int no;
15
16 @XlsColumn(columnName="名前")
17 private String name;
18
19 @XlsColumn(columnName="住所")
20 private String address;
21
22 // レコードが空と判定するためのメソッド
23 @XlsIgnorable
24 public boolean isEmpty() {
25
26 if(name != null || !name.isEmpty()) {
27 return false;
28 }
29
30 if(address != null || !address.isEmpty()) {
31 return false;
32 }
33
34 return true;
35 }
36}
3.17.1. IsEmptyBuilderを使った記述の簡単化
IsEmptyBuilder (ver.0.5から追加)を利用することで、より簡潔に記述することも可能です。
IsEmptyBuilder#reflectionIsEmpty(...)を利用して判定する場合、位置情報を保持するフィールドMap<String, Point> positionsなどは除外対象とする必要があります。独自に判定する場合、
IsEmptyBuilder#append(...)を利用します。さらに、
IsEmptyBuilder#compare(IsEmptyComparator)を利用することで独自の判定をできます。その際に、Lambda式を利用すると簡潔に記載できます。
1// ルートのオブジェクト
2@XlsSheet(name="シート名")
3public class UnitUser {
4
5 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
6 private List<User> users;
7
8}
9
10// レコードのオブジェクト
11public class User {
12
13 // マッピングしたセルの位置情報を保持する。
14 private Map<String, Point> positions;
15
16 // マッピングしたセルのラベル情報を保持する。
17 private Map<String, String> labels;
18
19 @XlsColumn(columnName="No.")
20 private int no;
21
22 @XlsColumn(columnName="名前")
23 private String name;
24
25 @XlsColumn(columnName="住所")
26 private String address;
27
28 // レコードが空と判定するためのメソッド
29 @XlsIgnorable
30 public boolean isEmpty() {
31 return IsEmptyBuilder.reflectionIsEmpty(this, "positions", "labels");
32
33 }
34
35 // 独自に判定する場合
36 public boolean isEmpty2() {
37 return new IsEmptyBuilder()
38 .append(name)
39 .compare(() -> StringUtils.isBlank(address))
40 .isEmpty();
41 }
42}
3.18. @XlsArrayOption
アノテーション @XlsArrayCells 、 @XlsLabelledArrayCells 、@XlsArrayColumns において、書き込み時の配列・リストの操作を指定するためのアノテーションです。 [ver.2.0+]
3.18.1. 書き込み時に配列・リストのサイズが不足している場合(overOperation)
アノテーション @XlsArrayOption を指定することで、書き込み時のセルの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が小さく、足りない場合の操作を指定します。デフォルト値である列挙型
OverOperation#Breakの値のとき、隣接するセルへの書き込みを中断します。列挙型
OverOperation#Errorの値のとき、書き込み処理をする前に、例外AnnotationInvalidExceptionをスローします。
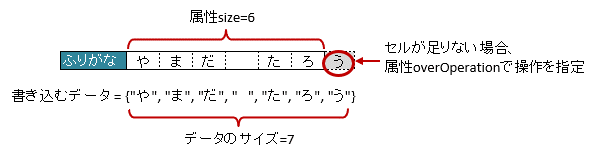
図 - 3.18.1 ArrayOption(overOperation)
1// 書き込むデータ
2String[] data = String[]{"や", "ま", "だ", " ", "た", "ろ", "う"};
3
4// マッピングの定義
5@XlsSheet(name="Users")
6public class SampleSheet {
7
8 @XlsLabelledArrayCells(columnName="ふりがな", type=LabelledCellType.Right, size=6)
9 @XlsArrayOption(overOperation=OverOperation.Error)
10 private String[] nameRuby;
11}
3.18.2. 書き込み時に配列・リストのサイズが余っている場合(remainedOperation)
アノテーション @XlsArrayOption を指定することで、書き込み時のセルの制御を指定できます。
属性
remainedOperationで、書き込み時にJavaオブジェクトの配列・リストのサイズに対して、属性sizeの値が大きく、余っている場合の操作を指定します。デフォルト値である列挙型
RemainedOperation#Noneの値のとき、隣接するセルへの書き込み、その後何もしません。列挙型
RemainedOperation#Clearの値のとき、隣接するセルへの書き込み、その後、余っているセルの値をクリアします。
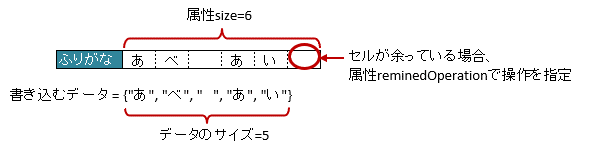
図 - 3.18.2 ArrayOption(remainedOperation)
1// 書き込むデータ
2String[] data = String[]{"あ", "べ", " ", "あ", "い"};
3
4// マッピングの定義
5@XlsSheet(name="Users")
6public class SampleSheet {
7
8 @XlsLabelledArrayCells(columnName="ふりがな", type=LabelledCellType.Right, size=6)
9 @XlsArrayOption(remainedOperation=RemainedOperation.Clear)
10 private String[] nameRuby;
11}
3.19. @XlsRecordOption
アノテーション @XlsHorizontalRecords 、 @XlsVerticalRecords において、書き込み時のレコードの操作を指定するためのアノテーションです。 [ver.2.0+]
3.19.1. 書き込み時に配列・リストのサイズが不足している場合(overOperation)
アノテーション @XlsRecordOption を指定することで、書き込み時のレコードの制御を指定できます。
属性
overOperationで、書き込み時にJavaオブジェクトのレコード数に対して、シートのレコード数が足りない場合の操作を指定します。デフォルト値である列挙型
OverOperation#Breakのとき、レコードの書き込みを中断します。列挙型
OverOperation#Copyのとき、指定すると上部のセルの書式を下部にコピーして値を設定します。@XlsVerticalRecordsのときは、左側のセルを右側にコピーして値を設定します。
列挙型
OverOperation#Insertのとき、行を挿入してレコードを書き込みます。その際に、上部のセルの書式をコピーします。@XlsVerticalRecordsのときは、サポートしていません。
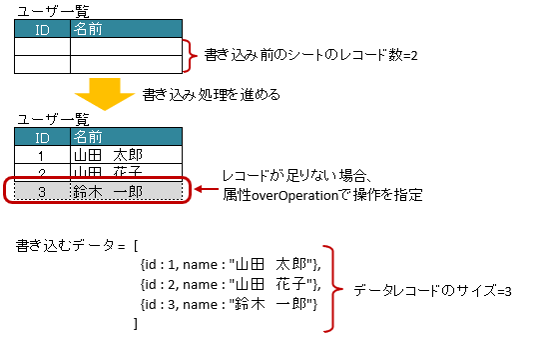
図 - 3.19.1 RecordOption(overOperation)
1// 書き込むデータ
2List<UserRecord> data = new ArrayList<>();
3data.add(new UserRecord(1, "山田 太郎"));
4data.add(new UserRecord(2, "山田 花子"));
5data.add(new UserRecord(3, "鈴木 一郎"));
6
7// マッピングの定義
8@XlsSheet(name="Users")
9public class SheetObject {
10
11 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
12 @XlsRecordOption(overOperation=OverOperation.Insert)
13 private List<UserRecord> records;
14
15}
3.19.2. 書き込み時に配列・リストのサイズが余っている場合(remainedOperation)
アノテーション @XlsRecordOption を指定することで、書き込み時のセルの制御を指定できます。
属性
remainedOperationで、書き込み時にJavaオブジェクトのレコード数に対して、シートのレコード数が余っている場合の操作を指定します。デフォルト値である列挙型
RemainedOperation#Noneの値のとき、レコードを書き込み、その後何もしません。列挙型
RemainedOperation#Clearの値のとき、レコードを書き込み、その後、余っているセルの値をクリアします。列挙型
RemainedOperation#Deleteの値のとき、レコードを書き込み、その後、余っている行を削除します。@XlsVerticalRecordsのときは、サポートしていません。
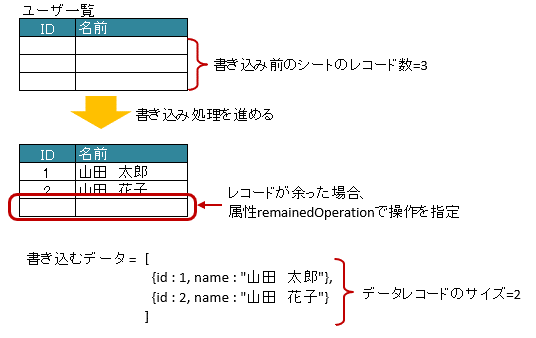
図 - 3.19.2 RecordOption(remainedOperation)
1// 書き込むデータ
2List<UserRecord> data = new ArrayList<>();
3data.add(new UserRecord(1, "山田 太郎"));
4data.add(new UserRecord(2, "山田 花子"));
5
6// マッピングの定義
7@XlsSheet(name="Users")
8public class SheetObject {
9
10 @XlsHorizontalRecords(tableLabel="ユーザ一覧")
11 @XlsRecordOption(remainedOperation=RemainedOperation.Clear)
12 private List<UserRecord> records;
13
14}
3.20. @XlsRecordFinder
アノテーション @XlsHorizontalRecords 、 @XlsVerticalRecords において、データレコードの開始位置が既存のアノテーションの属性だと表現できない場合に、任意の実装方法を指定するようにします。 [ver.2.0+]
属性
valueで、レコードの開始位置を検索するRecordFinderの実装クラスを指定します。属性
argsで、レコードの開始位置を検索する実装クラスに渡す引数を指定します。
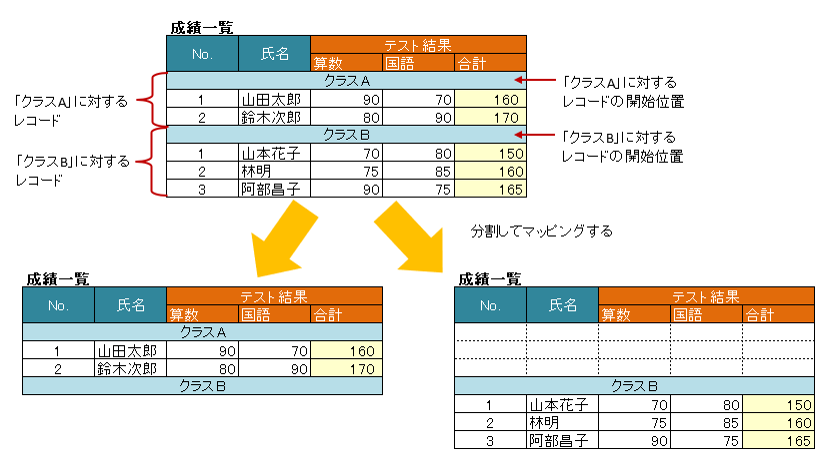
図 - 3.20.1 RecordFinder
1// マッピングの定義
2@XlsSheet(name="Users")
3public class SheetSheet {
4
5 // クラスAに対するマッピング定義
6 @XlsOrder(1)
7 // マッピングの終了条件が、「クラスB」であるため、terminalLabelを指定します。汎用的に正規表現で指定します。
8 @XlsHorizontalRecords(tableLabel="成績一覧", bottom=2, terminal=RecordTerminal.Border, terminateLabel="/クラス.+/")
9 // クラスAの見出しを探すために、属性argsでクラス名を指定します。
10 @XlsRecordFinder(value=ClassNameRecordFinder.class, args="クラスA")
11 private List<Record> classA;
12
13 // クラスBに対するマッピング定義
14 @XlsOrder(2)
15 // マッピングの終了条件が、終端のセルに罫線があるのため、terminalを指定します。
16 @XlsHorizontalRecords(tableLabel="成績一覧", bottom=2, terminal=RecordTerminal.Border, terminateLabel="/クラス.+/")
17 // クラスAの見出しを探すために、属性argsでクラス名を指定します。
18 @XlsRecordFinder(value=ClassNameRecordFinder.class, args="クラスB")
19 private List<Record> classB;
20
21}
22
23// クラス用の見出しのレコードを探すクラス
24class ClassNameRecordFinder implements RecordFinder {
25
26 @Override
27 public CellPosition find(ProcessCase processCase, String[] args, Sheet sheet,
28 CellPosition initAddress, Object beanObj, Configuration config) {
29
30 // アノテーション @XlsRecordFinder の属性argsで指定された値を元にセルを検索します。
31 final String className = args[0];
32 Cell classNameCell = CellFinder.query(sheet, className, config)
33 .startPosition(initAddress)
34 .findWhenNotFoundException();
35
36 // 見出し用のセルから1つ下がデータレコードの開始位置
37 return CellPosition.of(classNameCell.getRowIndex()+1, initAddress.getColumn());
38 }
39
40}
41
42// ユーザレコードの定義
43public class UserRecord {
44
45 @XlsColumn(columnName="No.", optional=true)
46 private int no;
47
48 @XlsColumn(columnName="氏名")
49 private String name;
50
51 @XlsColumn(columnName="算数")
52 private Integer sansu;
53
54 @XlsColumn(columnName="国語")
55 private Integer kokugo;
56
57 @XlsColumn(columnName="合計")
58 @XlsFormula(value="SUM(D{rowNumber}:E{rowNumber})", primary=true)
59 private Integer sum;
60
61 @XlsIgnorable
62 public boolean isEmpty() {
63 return IsEmptyBuilder.reflectionIsEmpty(this, "positions", "labels", "no");
64 }
65
66 // getter、setterは省略
67
68}
3.21. @XlsCommentOption
アノテーション @XlsComment 、 @XlsLabelledComment において、書き込み時のコメントの書式などを指定するためのアノテーションです。 [ver.2.1+]
また、フィールド Map<String, String> comments でコメントをマッピングするセルに対しても指定可能です。
3.21.1. 書き込み時にコメントの表示/非表示設定をする。
アノテーション @XlsCommentOption の属性 visible を指定することで、書き込み時にコメントの表示/非表示設定をできます。
true場合、表示する設定になり、常にコメントが表示されます。
既に設定されているコメントの設定よりも、アノテーションの設定が優先されます。

図 - 3.21.1 CommentOption(visible)
1// 書き込むデータ
2SampleSheet sheet = new SampleSheet();
3sheet.birthdayDescription = "yyyy/MM/dd の形式で設定してください。";
4sheet.setBirthdayComment("設定してください。");
5
6// マッピングの定義
7@XlsSheet(name="Users")
8public class SampleSheet {
9
10 private Map<String, String> comments;
11
12 @XlsCommentOption(visible=false)
13 @XlsLablledComment(label="誕生日")
14 private String birthdayDescription;
15
16 @XlsCommentOption(visible=true)
17 @XlsLabelledCell(label="誕生日", type=LabelledCellType.Right)
18 private LocalDate birthday;
19
20 // 誕生日の値セルのコメントの設定
21 public void setBirthdayComment(String comment) {
22 if(comments == null) {
23 this.comments = new HashMap<>();
24 }
25 this.comments.put("birthday", comment);
26 }
27
28}
3.21.2. 書き込み時にコメントの枠サイズを指定する
アノテーション @XlsCommentOption の属性 verticalSize / horizontalSize を指定することで、書き込み時のコメントの枠サイズを指定できます。
属性
verticalSizeにて、コメント枠の縦サイズを指定します。単位は行数です。
既にコメントが設定されている場合は、この設定は無視されます。
属性
horizontalSizeにて、コメント枠の横サイズを指定します。単位は列数です。
既にコメントが設定されている場合は、この設定は無視されます。
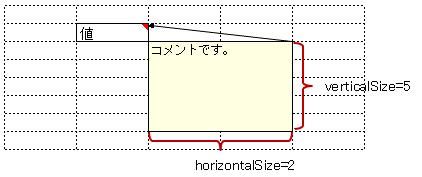
図 - 3.21.2 CommentOption(verticalSize/horizontalSize)
1// マッピングの定義
2@XlsSheet(name="Users")
3public class SampleSheet {
4
5 @XlsCommentOption(verticalSize=5, horizontalSize=2)
6 @XlsCellComment(address="B2")
7 private String value;
8
9}
3.21.3. 書き込み時に既存のコメントを自動削除する
アノテーション @XlsCommentOption の属性 removeIfEmpty を指定することで、書き込むコメントの値が空のとき、既存のコメントを自動削除できます。
属性 removeIfEmpty の初期値は false で削除されません。
1// マッピングの定義
2@XlsSheet(name="Users")
3public class SampleSheet {
4
5 @XlsCommentOption(removeIfEmpty=true)
6 @XlsCellComment(address="B2")
7 private String value;
8
9}
3.21.4. コメントの読み込み、書き込みの処理の実装を切り替える
アノテーション @XlsCommentOption の属性 handler にて、コメントの処理を独自実装に切り替えることができます。
標準のコメントの処理は、 CellCommentHandler の実装クラス DefaultCellCommentHandler であるため、通常はこのクラスを継承してカスタマイズします。
全体の処理を切り替えたい場合は、システム設定 の CellCommentOperator のプロパティ commentHandler を変更します。
1@XlsSheet(name = "独自実装")
2public class CustomHandlerSheet {
3
4 private Map<String, CellPosition> positions;
5
6 private Map<String, String> labels;
7
8 private Map<String, String> comments;
9
10 @XlsSheetName
11 private String sheetName;
12
13 @XlsLabelledCell(label = "標準の処理", type = LabelledCellType.Right)
14 private String value1;
15
16 @XlsCommentOption(handler = CustomCellCommentHandler.class)
17 @XlsLabelledCell(label = "独自実装の処理", type = LabelledCellType.Right)
18 private String value2;
19
20}
21
22/**
23 * カスタマイズしたセルのコメント処理
24 */
25public class CustomCellCommentHandler extends DefaultCellCommentHandler {
26
27 public CustomCellCommentHandler() {
28 super();
29 // 初期設定値の変更
30 setMaxHorizontalSize(5);
31 setMaxVerticalSize(4);
32 }
33
34 // 読み込み時の処理
35 @Override
36 public Optional<String> handleLoad(final Cell cell, Optional<XlsCommentOption> commentOption) {
37
38 Optional<String> comment = super.handleLoad(cell, commentOption);
39
40 // 改行を除去する。
41 return comment.map(text -> text.replaceAll("\r|\n|\r\n", ""));
42 }
43
44 // 書き込み時の処理
45 @Override
46 public void handleSave(final Cell cell, final Optional<String> text, final Optional<XlsCommentOption> commentOption) {
47
48 // 改行を除去する。
49 text.map(comment -> comment.replaceAll("\r|\n|\r\n", ""))
50 .ifPresent(comment -> super.handleSave(cell, Optional.of(comment), commentOption));
51
52 }
53
54}
3.21.5. 書き込み時にコメントの枠サイズを自動設定する
アノテーション @XlsCommentOption の属性 verticalSize / horizontalSize でコメント枠のサイズを指定しない場合は、
書き込むコメントの文字数、改行数によって自動的に設定されます。
ただし、コメント枠のサイズは、行数、列数で指定するため、コメントが表示される領域のセルのサイズが他と異なる場合、 意図したサイズにならない場合があります。
その際は、アノテーション @XlsCommentOption を使用してサイズを直接指定します。
または、標準の自動設定値を変更します。 ここでは、標準の設定値を変更します。
標準のコメントの処理は、 CellCommentHandler の実装クラス DefaultCellCommentHandler で指定されます。
この実装は、システム設定 の CellCommentOperator のプロパティ commentHandler で保持しています。
初期値では、コメントの縦サイズは最大4行分まで、横サイズは最大3列分となります。
1// コメントを処理するハンドラのインスタンスを生成します。
2DefaultCellCommentHandler commentHandler = new DefaultCellCommentHandler();
3
4// コメントの縦サイズの最大サイズを指定します。
5commentHandler.setMaxVerticalSize(5);
6
7// コメントの横サイズの最大サイズを指定します。
8commentHandler.setMaxHorizontalSize(5);
9
10// システム設定値を変更します。
11XlsMapper xlsMapper = new XlsMapper();
12xlsMapper.getConfiguration().getCommentOperator().setCommentHandler(commentHandler);